「データ」「情報」「知識」の含意からドメイン駆動設計と2種のインピーダンス・ミスマッチを辿る考察
FOLIO Advent Calendar 2020 17日目です。
「データ」「情報」「知識」の含意から、ドメイン駆動設計、そして、ソフトウェア設計の現実に存在するインピーダンスミスマッチまでを考えてみるエントリです。 本エントリは、主に次の論文「データ・情報・知識の含意と相互関係の二重性について」(関口 (2016))を多々援用します*1。 これは、情報経営学分野の知見をソフトウェア設計に持ち込む試みです。
「データ」「情報」「知識」 日本語と英語の違い
「データ」と「情報」という言葉はあまり区別されずに使われることが多いものです。 関口 (2016) では、Oxford Dictionaryと広辞苑をひいて次のように分析しています。

関口 (2016) より引用
詳しくは論文を参照してもらうのが良いですが、述べられていることはおおよそ次のことです。 なお、各単語の記載方法は論文にならって、日本語はカッコをつけ、英語は英語表記のまま使用します。
- 日本語の「情報」は「データ」と「知識」を含む極めて広い含意を持つ
- 英語の information も data と knowledge の大部分を含む極めて広い含意を持つ(この点では共通している)
- 「情報」は「来るもの」との意味合いが強く、言葉としてなんらかの媒体に記述された形式的なものを主に指す(役に立つ内容を持っていることが期待される形式情報)
- 一方で information には knowledge と重なる部分の「(求めて)与えられる」の意味合いもあり、積極的に獲得するという能動さがある
- 「データ」はコンピュータで処理されないものを含まないが、dataはコンピュータで処理しないが意図的に集めた形式情報も含むなど一致しない*2
- 「知識」は「知っている」事柄を指し、「(積極的に)獲得する」側面が希薄だと考えられる
この図からは、日本語において「知識」と「知能」の間に空白があることも読み取れます。 関口 (2016) は「情報」を延長して、ここに「意味情報」という言葉を置き、形式化されていない情報も扱うことを試みています。
逆Y型モデル
関口 (2016) は、DIK階層モデルをもとに逆Y型モデルを構築しています。 注意点として、この逆Y型モデルは情報経営学の流れで提言されているため、ある企業における活動が主眼にあるように思います。

このなかで「意味情報」とは、「(形式)情報」を受け取った各利用者個人が、そこから「役に立つ」内容として抽出した形式化されていない情報を指すと定義しています。 少し難しい定義ですが、たとえば、自転車の乗り方を教わったとき、実際に乗ってみることで「はじめに少し勢いをつける」という skill と一緒に獲得される情報を指していると思われます。 これはよく暗黙知として述べられる例でもありますが、「未だ形式化(言語化)されていない知識」と「知識を利用する際の方法が暗黙的であること」の2つの概念がある点には留意が必要です*3*4。
関口 (2016) は情報と知識を区別して論じていますので、意味情報は暗黙知と一致しません。 あくまで、知識を知るための素材として情報*5がまずあり、知識は取り込まれ抽出された結果だと考えることが自然のようです*6。 加えて、データから情報に変換するにあたり、知識*7は利用者の活動のなかで暗黙的に使われることも述べていますので、逆Y型モデルに示されるように相互補強的です。
ここでの(作成者にとっての)知識は暗黙知と峻別することは困難であり、いわゆる形式知は(利用者にとっては)形式情報でしかないと述べている点は興味深いです。 これは、作成者の文脈と利用者の文脈で二重性があることをもって指摘されています。
- 作成者
- 意味情報をデータに変換する、データを分析・総合したり、経験を形式知として記述したりして形式情報に変換する人
- 利用者
- そのようにして作成された形式情報を意思決定に利用する人
つまり、利用者にとって(自身の)暗黙知にまで昇華できるかは作成者の意図とは切り離されており、いかに意味や意義を見出すかが課題であることを示しています。 また、情報システム技術者にとって、意思決定者のために(図下部の)「作成者」としてのDIK階層をどのような構成にするかが課題であるとして提起されています。
情報システムの利用者である意思決定者が課題を解決するのに効果的な(意味)情報を受け取れるためには,情報システム技術者が利用者の課題を具体的に把握し理解する必要がある。 (中略) つまり,利用者が必要とする意味情報と作成者が提供できる形式情報について共通の理解を持てるように,両者が適切な経験と知識を共有しなければならない。
ここから、情報システム技術者が中心となって、これらを綜合する営みが重要であると読み取れるように思います。 関口 (2016) が「効果的な意味情報の具体的な内容を、情報利用者ですら自覚することが少ない」と指摘するように、両者の文脈を綜合する役割が求められるのでしょう。
ドメイン駆動設計とドメインモデル
情報システム開発の世界で、ひとつの考え方として「ドメイン駆動設計」(以下、DDD)があります。 DDDは、ドメイン実務者とシステム技術者が一緒になってモデリングし、その成果であるドメインモデルをもとにシステム開発を行うものです。
書籍「エリック・エヴァンスのドメイン駆動設計」を参照することは重いので、ここではEric Evans自身によって書かれた DDD Reference を参照します*8。
まず domain の定義を確認します。 強調は筆者(私)によるものです。
A sphere of knowledge, influence, or activity. The subject area to which the user applies a program is the domain of the software.
knowledge という言葉がまさに使われています。 関口 (2016) では、knowledgeの説明として次のように述べています。
knowledgeは経験や教育を通して得る facts,information あるいは理論的な理解ばかりではなく,経験や教育を通して身につける能力も含む語として使われる。
次に model の定義を確認します。
A system of abstractions that describes selected aspects of a domain and can be used to solve problems related to that domain.
これらからドメインモデルとは、ドメインにある問題を解決するために、知識*9を含むドメインのある側面を意図的に選択し抽象化してシステム*10として仕立てたものであることが読み取れます。
非常に観測範囲は狭いものですが、日本語のドメイン駆動設計の解説などでは、前述の日本語の意味、つまり、形式情報を主だった相手にして述べられているものが多々あるように感じます。 一方で、英語の意味としては、それだけではなく自身の経験などを通して、積極的に獲得しにいくことが含まれていました*11*12。 この差は小さなもののようにみえますが、大きな差です。 (Evansが提示した)ドメインモデルは、形式化されていない意味情報や(作成者文脈の)暗黙知をも射程にいれて、ドメインに携わる人々の生き生きとした intelligence に裏打ちされた「実践の知」を本来考えるべきなのではないでしょうか。
前述の逆Y型モデルにあてはめて考えれば、情報システム技術者としてみたとき、ドメインモデルは意味情報に相当すると考えられます*13。 また、DDDで戦略パターン - そして、特に重要なPrinciple - の1つとしてあげられているユビキタス言語は形式情報に相当すると思います。 つまり、ドメインモデルを探求するという営みが、関口 (2016) が課題としてあげた綜合する営みに適うのではないかということです。
Whirlpool process と組織的な知識創造
DDDの文脈では、Whirlpool process という(「使える」)モデル探求のための方法が提示されています。
ぐるぐるDDD/Scrumとして、スクラムを絡めて解説された情報も見つかります。
この方法が述べていることは、シナリオとモデルのフィードバックループに、コードによる探査を加えることで、使える(=シナリオに適していて、システムにも組み込める)モデルを探しましょうということと思っています。 この探索的なソフトウェア設計のプロセスは、逆Y型モデルからも説明することができます。
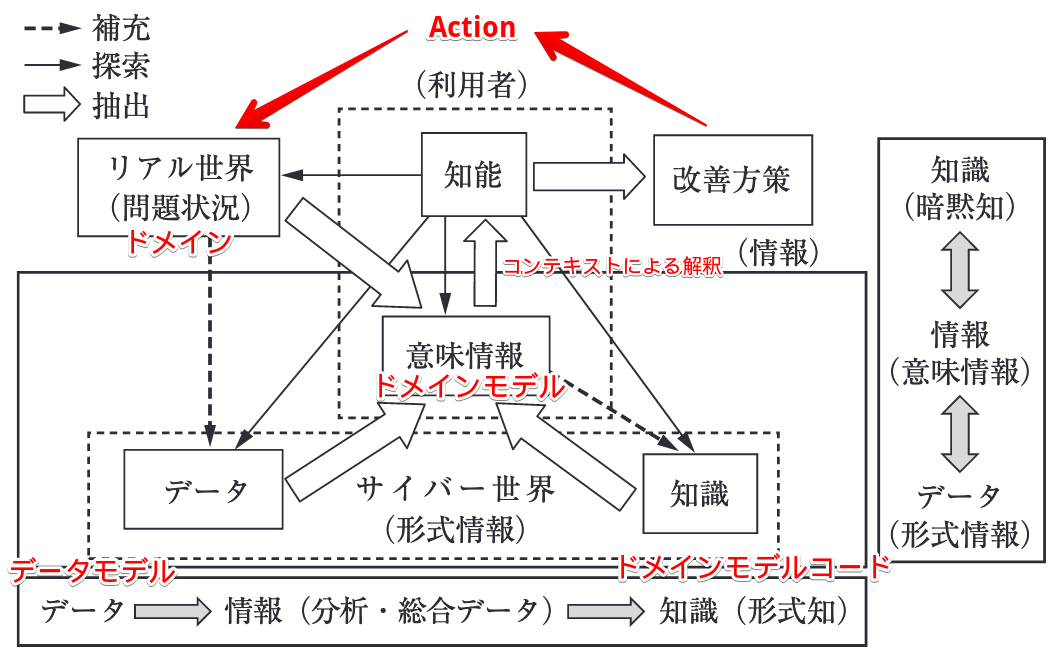
ドメインの実務者との対話を通じて、実務者(またはその関係者)が提供可能なデータは、ドメインの理解を深めるなかで形式情報や(仮説としての)ドメインモデルのコード表現へと昇華されていきます。 知能や意味情報から探索と補充の線が知識・形式知(ドメインモデルのコード表現)へとつながっていることに、情報経営学分野との一致をみることができます。 このプロセスにおける「改善方策」は、ドメインモデルのコード表現の改善と同義と考えることで、それをリアル世界のシナリオに適用させること(challenge model)で新たな意味情報やデータが得られ、また次のサイクルがまわると考えられます*14。
そして、重要なのは、逆Y型モデルを仲介することによって、有名な組織的知識創造プロセスであるSECIモデルにも到達することができる点です。 つまり、いち開発プロセスがフラクタル・自己言及的に組織の知識創造プロセスに組み込まれることを示唆できるということです。 SECIモデル(それに付随する種々の補強含む)に関しては、論旨から外れるため本エントリでは踏み込みません*15。
2種のインピーダンス・ミスマッチ
翻って、ソフトウェア設計に目を移すと、いわゆるデータモデルとドメインモデル(コード)のインピーダンス・ミスマッチの問題が話されることがあります。 データモデルは、先の定義に準じて、物事に関する諸事実の描写とここでは定義しておきます*16。
また、第8回 ソフトウェア工業化の未来(2/2) - @ITのなかで、要求と成果物の間にインピーダンス・ミスマッチが存在することが指摘されています。
どんなソフトウェア開発であっても、「開発対象のソフトウェアが実現すべき要求(機能要求、非機能要求)」と「要求を実現した成果物」の間には、インピーダンス・ミスマッチが存在する。 ここでいうインピーダンス・ミスマッチとは、両者の間に完全に可逆的なトレーサビリティの構築ができず、モデルで表現した場合は、要求モデルとコンポーネントなどの資産モデル間にモデルの意味的なギャップが存在することである。 (中略) その本質的な理由は、要求が「何をしたいか」を表現し、比較的短期で変化しやすい傾向にあるのに対して、ソフトウェア資産が「どうあるべきか」を表現し、資産という性格上、長期に変化しないことが望まれるためである。
以上から、2種のインピーダンス・ミスマッチをみてとれます。
- 「事実たるデータ」と「知識たるモデル表現」
- 「要求モデル」と「資産モデル」
これらのインピーダンス・ミスマッチは、成果である右にあるものが、意味情報の影響を少なからず受けるために生じるものとみています。 ただし、前者のインピーダンス・ミスマッチは図の横軸(図下部)で起きることに相当するのに対して、後者は図の縦軸(図右部)で起きることに相当する点に注意が必要です。 前者のデータモデルとドメインモデルコードのインピーダンス・ミスマッチは、(実装にも起因する)形式表現またはモデリングパラダイムの違いと捉えることは自然かと思います。 後者の要求モデルと資産モデルのインピーダンス・ミスマッチは、要求の変化を図中の「改善方策」の出力とほぼ同義と考えれば、要求モデル=意思決定者(利用者)と資産モデル=形式情報との間の問題と考えられます。
データモデルとドメインモデルコードのインピーダンス・ミスマッチの解決
本エントリに先んじて、このインピーダンス・ミスマッチは受け入れていくべきか、それとも解消していくべきかを社内で聞いてみました。 そこであがったコメントは大まかに次のものです。
- データストアの特性/実装に合わせたデータモデルを定義するために発生するのではないか
- 扱うデータに時系列な要素が含まれてくるとギャップが生まれやすいのではないか
- ドメインイベントとしてのスナップショットを記録するなら、そこまでギャップは生じないが、イベントのリプレイの結果を使いたいとなると時系列にならざるを得ないのでミスマッチが発生する
- データモデルには過去の歴史で時系列の問題をどうやって解決してきたかの知見があるので、そっちに寄せていくのが現実解として取られやすいのかなと思う
後者は特にデータ分析に携わる見方であり、データモデリングに際してイベントとリソースに着目することの重要性を指しています*17。 情報が欲しい人が、情報が欲しいときに、取り出せるようなデータ設計をなるべくしたいという話だと理解しています。 次の記事にまとめられています*18。
また、次の記事では、モデリングパラダイムによるギャップであると指摘があります。
以上のことから、選択した技術に適したモデリングパラダイムを用いるために、インピーダンス・ミスマッチが起きると考えられます。 一般には、これはO/Rマッピングを用いることで解決(軽減)されます。 データはデータとして、知識表現は知識表現として、適したモデリングを選択し、ギャップがあることを受け入れたうえで、仲介役としてO/Rマッパーを導入している構図かと思います。
このとき、設計判断を行う世界と実際のデータ利用の世界の間には相互に影響を及ぼしあう関係がありそうです。 その際には意味情報が影響源となっていると考えると、この意味情報の存在を表現していくことがヒントになるかもしれません。
要求モデルと資産モデルのインピーダンス・ミスマッチの解決
前掲の筆者が加工した図では「コンテキストによる解釈」を書き加えていました。 意味情報から知識となるまでには、もう一段階の抽出が行われる点にも注意が必要なのです。 ここがインピーダンス・ミスマッチの生じるポイントでしょう。
第8回 ソフトウェア工業化の未来(2/2) - @ITでは、解決アプローチについても提示されています。
- 資産モデルを要求モデルに近づけギャップを埋める
- 要求モデルを資産モデルに近づけギャップを埋める
- 要求モデルでも資産モデルでもない中間のモデルを用意して、両者のモデルを中継する
3点目のアプローチはサブジェクト指向に言及があります。 サブジェクト指向については、次の記事が参考になります*19。
tanakakoichi9230.hatenablog.com
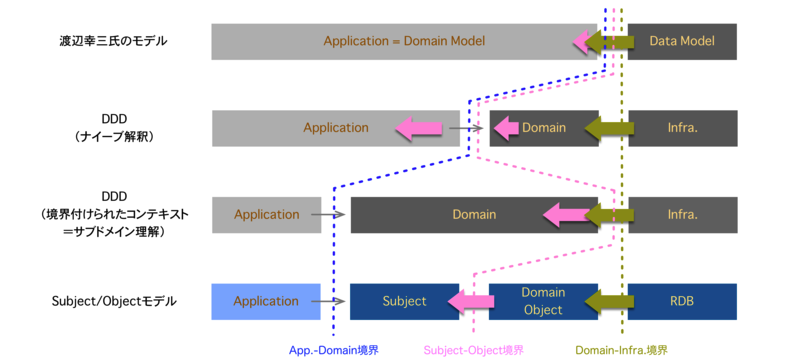
図に示されるように、Subject - Object に着目することがヒントになるかもしれません。
まとめ
関口 (2016) をひいて、日本語と英語のそれぞれの言葉の含意から、逆Y型モデルがソフトウェア設計の文脈にも重ねられることをみてきました。 世の中に日本語「情報」、英語「情報」は溢れていますが、それはあくまで形式情報であり、意味情報は自身で獲得していくことが必要です。 また、それらの「情報」のなかで使われる言葉の含意は、言葉を使う人によってブレがあるため注意が必要なことも示しました。
論文のなかで課題として残された、(形式)情報の作成者と利用者の文脈の綜合について、ドメイン駆動設計、そして、その探索的プロセスが一つの解となる可能性を提起しました。 さらに、逆Y型モデルを仲介として、組織的知識創造理論へのフラクタルな適合もできる可能性を示唆しました。 この深掘りは課題として残されています。
最後に、実際のソフトウェア設計の現実として、2種のインピーダンス・ミスマッチの存在をたどりました。 1つは「DB技術によるミスマッチ(データ先行)」、1つは「知識探求によるミスマッチ(ドメイン先行)」ともいえ、それぞれでどのような解決アプローチがあるのかをみました。 つまり、モデリングパラダイムの違い、または、変化の速度の違いがインピーダンス・ミスマッチを生んでいるということです。
現実には事業の成長によって、乖離は広がりえます。 このインピーダンス・ミスマッチ、セマンティックギャップはむしろ積極的に受け入れるべきではないかなと思います。 先のデータモデルとドメインモデルコードのインピーダンス・ミスマッチでは、仲介役を用意することで解決を図っていました。 要求モデルと資産モデルのインピーダンス・ミスマッチにおいても、3つのアプローチのうち、1つは同様に仲介役を用意することが提示されていました。 これらは、いずれにしても左から右に変換するにあたって、影響を及ぼした意味情報をモデル化することが、ミスマッチを解決(軽減)するアプローチといえるように思います。
意味情報は、その定義から暗黙知よりもまだ意識的に表現できる可能性があります。 その一端がサブジェクト指向などでしょう。 インピーダンス・ミスマッチを解決(軽減)する試みとして、意味情報に着目することは有益なように思います。
あとがき:エモパート
ここからは、あとがきとして口語で書こうと思います。
自分でここまで書いておいてなんですが、読む人いる…?というくらいゴツいエントリになってしまったなぁと感じています。 今、このあとがきを書いている時点で文字数換算で12000文字を超えてます。 もちろん、がんばって書いているので、読まれて欲しい気持ちは結構あるんですが、いち消費コンテンツのレベルではない…。 2000ブクマ欲しい*20。
本エントリでは、情報経営学分野の知見を持ち込むことで、ソフトウェア設計という活動が組織的知識創造活動の「理論」とつながれることを意識しました。 お気持ちで書かれたものも大事だし、むしろ、それくらいの方が行動変容を促される人もいたりすると思うのですが、個人的には「理論」というのは必要不可欠な要素です。 もう少し言うと、「理論立てる」という行為ですね。 理論があるからこそ、それを下敷きに議論もできるし、改善していくこともできます。 Theory in Practice という言葉もあるように、実践のなかで思ったこと・感じたこと・考えたことを理論立てていくことが次に繋がるのだろうと。
また、ソフトウェア設計の世界の外で理論化されているモノ(形式情報)があれば、本エントリのように持ち込むこともできるし、逆に輸出することもできます*21。 そうやって、他分野にまたがって、コミュニティの交流が行われることが、発展には必要だろうと思うのです。 みたいなことは、Eric Evansも言っているはず?*22
関口 (2016) 論文を読んだのがつい最近で突貫で書いたので、本エントリの穴はたくさんあるかもしれません。 でも、穴があるからダメではなくて、反証をもとに改善を加えていくコトが大事ですよね。 穴を見つけたらフィードバックをください。
それから、本当は具体的なお題をもとにインピーダンス・ミスマッチを考える予定だったのですが、その前振りで力尽きました…。 たとえば、契約と一口に言っても、その内容が金融商品取引にかかるものであれば、金融商品取引法(以下、金商法)の遵守が必要となります。 金商法では、契約締結の前に契約締結前交付書面を交付し、また、契約締結となった際にはすみやかに契約締結時交付書面を交付することが求められるなど、一般の契約よりも追加要件があります。 ビジネスロジック・ドメインモデルとしては、一般の契約と金融商品取引契約とでモデル化するところかと思いますが、では、データモデルはどうか?みたいなところで例になるかなと思っていたんですが、これはまた別の機会にしましょう…*23。
それでは、来年もよろしくお願いします。 良いお年を!
References
- 関口 恭毅 (2016) 「データ・情報・知識の含意と相互関係の二重性について」 商学論纂 57(5・6), 209-249
- 赤尾 充哉 (2013) 「知識と組織制度についての考察」 (PDF) 慶應義塾大学大学院商学研究科 『2012年度大学院高度化推進研究プロジェクト 成果報告書』
- DDD Reference - Domain Language
- Whirlpool Process of Model Exploration - Domain Language
- ぐるぐるDDD/Scrum - モデリングと実装のうずまきをまわそう
- ぐるぐるDDDは何を目指しているのか
- 「DDD」にまつわる諸課題の整理 - Qiita
- データモデルはドメインモデルに先行する: 設計者の発言
- ドメインとデータ、サブジェクトとオブジェクト、および、事実は常に事実であり、真実は常に仮説である、という話 - たなかこういちの開発ノート
- 第8回 ソフトウェア工業化の未来(2/2) - @IT
- 連載:次世代開発基盤技術“Software Factories”詳解 第4回 フィーチャの実現法とサブジェクト指向パラダイム(3/3) - @IT
- 設計者やプログラマーは「見えない問題の探求者」、創造の暗黙知を継承せよ | 日経クロステック(xTECH)
- パタン・ランゲージとオブジェクト指向の関係、あるいは分析と総合の動的平衡 - assertInstanceOf('Engineer', $a_suenami)
- https://corp.folio-sec.com/thespecialone/jobs/
*1:紀要論文ではありますが、著者は情報経営学分野での活躍があり十分参考になるものと思います
*2:dataは「informationよりも新しい言葉で、哲学用語であったものが、情報処理分野でも使われるようになった」と述べられており、哲学ではどのように生まれてきたのか調べるのも面白そうですね
*3:前者は野中郁次郎が提示した概念で、後者はマイケル・ポランニーが提示した概念です。より詳しくは赤尾 (2013) を参照
*4:ただし、関口 (2016) も赤尾 (2013) も、野中郁次郎の古い論文等を参照しているため、最近の考え方と異なる(補強がある)ことは注意が必要かなと思いますが、論旨には影響がないので割愛
*5:形式情報と意味情報の両方を含む
*6:関口 (2016) はEnglishを引用して、情報は「文脈に置かれたデータ」、知識は「文脈に置かれた情報」と述べています。これは、事実→意味→重要性の理解という段階です。
*7:知的能力から分離して認識することが困難な知識
*8:今見るとリンクが切れていますね… https://www.domainlanguage.com/wp-content/uploads/2016/05/DDD_Reference_2015-03.pdf からPDFが参照できます
*9:繰り返しますが、これは英語の knowledge の意味です
*10:ここでの「システム」は、教義のITシステムではなく広義の(一般システム理論が述べたような)システムを指すものと思います
*11:ここには文化的習慣的な隔たりを感じますが、趣旨と外れるため深掘りはしません
*12:もっとも、英語圏といえどもITの文脈では data と information はあまり区別されないことも多々あります
*13:ここで形式情報と考えないのは、ユビキタス言語をもって会話を重ねても、取り込む個人によって内に構築される考え方、つまりモデルは異なるものになると考えるからです。これはたとえばUMLなどを用いて図示する行為は、取り込んだ暗黙知によって形式情報に出力して確認している行為であり、チームメンバーの間で意味情報を強化する行いでしかなく、実際に意味情報から知識へと昇華してプログラミングすることは、あくまでその個人の営みであるからということです。
*14:なお、ここでのデータは、関口 (2016) がMcDonoughを引用して述べる「データは交信の対象となる形式情報全般,つまり,いわゆるデータ,分析・総合して形成した形式情報および形式知を指す」とニュアンスは近いかと思います
*15:関口 (2016) では情報冗長性の重要性に着目して検討を行っています。これもまた興味深いところです。
*16:データモデルという言葉の統一された定義は、ここではあまり重視しませんが、身近なものでリレーショナルモデルあたりを想像しています
*17:ここでも、組織的知識創造理論における情報の冗長性やドメインイベントBusなどを絡めて考察することが可能に思いますが、それはまたの機会に譲ります
*18:参照先の textafm 第3回「Low-Code Development」は非常に良いです
*19:個人的にはイデア論は推していないので、あくまでものの見方の一つとして参考にするくらいが良いと思います
*20:同僚が同アドベントカレンダーで2000ブクマを突破したことによるハイコンテクストなギャグです
*21:情報経営学は「情報」とつくだけ親和性が高いのですが、それでもなんというか現場にいて、そういった世界のキャッチアップってあまりされないかなと思うわけで、このエントリが一助になればいいなとかは思います
*22:今見直すと本当に拙訳で申し訳ないんですが Eric Evans氏はドメイン駆動設計(DDD) は未完成だと述べた もあります…
*23:もっとも、論理設計では分かれていて、物理設計で1つのテーブルにする、というくらいの話になるだけかもしれません